测试用缓冲区溢出代码 在下面的程序示例中,我们将研究基于堆栈的缓冲区溢出是如何发生的。
我们将使用标准的 C gets() 易受攻击的函数(从标准输入读取并存储在缓冲区中而不进行边界检查)并且溢出将发生在 Test() 函数中。 Test() 函数的缓冲区最多只能容纳 3 个字符加上 NULL,因此 4 个或更多字符应该溢出其缓冲区,我们将尝试演示覆盖保存的 ebp 和 Test() 的返回地址。 测试是在 Linux Fedora Core 3 上完成的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <unistd.h> void Test () { char buff[4 ]; printf ("Some input: " ); gets(buff); puts (buff); } int main (int argc, char *argv[ ]) { Test(); return 0 ; }
BUFFER OVERFLOW PROGRAM EXECUTIONS 接着我们通过输入3,5,8和12个字符来运行代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [bodo@bakawali testbed5]$ ./testbuff Some input: AAA AAA [bodo@bakawali testbed5]$ ./testbuff Some input: AAAAA AAAAA Segmentation fault [bodo@bakawali testbed5]$ ./testbuff Some input: AAAAAAAA AAAAAAAA Segmentation fault [bodo@bakawali testbed5]$ ./testbuff Some input: AAAAAAAAAAAA AAAAAAAAAAAA Segmentation fault
显然,输入3个字符就可以了,但是超过3个字符(这里是5、8和12个字符)会产生分段错误,程序终止以避免其他不良后果。 好吧,有两个函数使用 buff 缓冲区。 那么,哪个函数的缓冲区(gets() 或 puts())会产生分段错误或者哪个函数已经溢出? 留给你去寻找答案。
DEBUGGING THE BUFFER OVERFLOW PROGRAM 让我们使用 gdb 调试程序,看看这里到底发生了什么
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 [bodo@bakawali testbed5]$ gdb testbuff GNU gdb Red Hat Linux (6.1post-1.20040607.43rh) Copyright 2004 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux-gnu"...Using host libthread_db library "/lib/tls/libthread_db.so.1". (gdb) break main Breakpoint 1 at 0x8048422: file testbuff.c, line 14. (gdb) disass main Dump of assembler code for function main: 0x08048406 <main+0>: push %ebp 0x08048407 <main+1>: mov %esp, %ebp 0x08048409 <main+3>: sub $0x8, %esp 0x0804840c <main+6>: and $0xfffffff0, %esp 0x0804840f <main+9>: mov $0x0, %eax 0x08048414 <main+14>: add $0xf, %eax 0x08048417 <main+17>: add $0xf, %eax 0x0804841a <main+20>: shr $0x4, %eax 0x0804841d <main+23>: shl $0x4, %eax 0x08048420 <main+26>: sub %eax, %esp 0x08048422 <main+28>: call 0x80483d0 <Test> 0x08048427 <main+33>: mov $0x0, %eax 0x0804842c <main+38>: leave 0x0804842d <main+39>: ret End of assembler dump. (gdb) disass Test Dump of assembler code for function Test: 0x080483d0 <Test+0>: push %ebp 0x080483d1 <Test+1>: mov %esp, %ebp 0x080483d3 <Test+3>: sub $0x8, %esp 0x080483d6 <Test+6>: sub $0xc, %esp 0x080483d9 <Test+9>: push $0x8048510 0x080483de <Test+14>: call 0x8048318 <_init+88> 0x080483e3 <Test+19>: add $0x10, %esp ;_init stack clean up 0x080483e6 <Test+22>: sub $0xc, %esp 0x080483e9 <Test+25>: lea 0xfffffffc(%ebp), %eax ;load effective address pointer [ebp-4] into eax 0x080483ec <Test+28>: push %eax ;push the pointer onto the stack 0x080483ed <Test+29>: call 0x80482e8 <_init+40> 0x080483f2 <Test+34>: add $0x10, %esp ;_init stack clean up 0x080483f5 <Test+37>: sub $0xc, %esp 0x080483f8 <Test+40>: lea 0xfffffffc(%ebp), %eax 0x080483fb <Test+43>: push %eax 0x080483fc <Test+44>: call 0x80482f8 <_init+56> 0x08048401 <Test+49>: add $0x10, %esp ;_init stack clean up 0x08048404 <Test+52>: leave 0x08048405 <Test+53>: ret End of assembler dump.
通过反汇编程序,虽然我们只声明了一个有4个元素(4个字节)的数组,但可以看到已经为局部变量和Test()函数的缓冲区分配了20个字节(0x8 + 0xc)。 让我们深入挖掘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [bodo@bakawali testbed5]$ gdb -q testbuff Using host libthread_db library "/lib/tls/libthread_db.so.1" . (gdb) break main Breakpoint 1 at 0x8048422: file testbuff.c, line 14. (gdb) r Starting program: /home/bodo/testbed5/testbuff Breakpoint 1, main (argc=1, argv=0xbfea3064) at testbuff.c:14 14 Test(); (gdb) s Test () at testbuff.c:7 7 printf ("Some input: " ); (gdb) 8 gets(buff); (gdb) Some input: AAA 9 puts(buff); (gdb) x/x $esp 0xbfea2fb0: 0x00000000 (gdb) x/x $ebp 0xbfea2fb8: 0xbfea2fd8 (gdb) x/x $ebp -4 0xbfea2fb4: 0x00414141 (gdb) x/s 0xbfea2fb4 0xbfea2fb4: "AAA" (gdb)
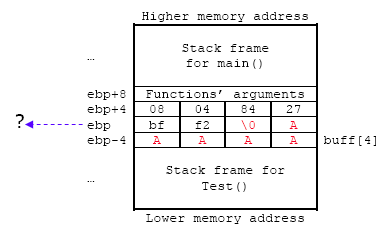
该程序的堆栈框架图如下所示。 buff[4] 存储在 Test() 函数堆栈帧的局部变量缓冲区中。 请记住,我们这里没有函数的参数。 字符“A”的十六进制为 41(红色标记)。
如果输入的是“AAA”的三个字符,则buff[4]数组正确填充三个字符+NULL。
这里的 ebp+4 即 call 指令的下一条指令的位置,即08048427
1 2 3 0x08048422 <main+28>: call 0x80483d0 <Test> 0x08048427 <main+33>: mov $0x0, %eax
当我们输入五个字符“AAAAA”时,保存的 %ebp 的某些区域将被覆盖,如下所示,使保存的保存 main() 堆栈帧指针的 %ebp 不再有效。 稍后恢复此堆栈帧指针时,它将指向错误或未定义的堆栈帧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 (gdb) r The program being debugged has been started already. Start it from the beginning? (y or n) y Starting program: /home/bodo/testbed5/testbuff Breakpoint 1, main (argc=1, argv=0xbff2d6a4) at testbuff.c:14 14 Test(); (gdb) s Test () at testbuff.c:7 7 printf("Some input: "); (gdb) 8 gets(buff); (gdb) Some input: AAAAA 9 puts(buff); (gdb) x/x $ebp 0xbff2d5f8: 0xbff20041 (gdb) x/x $ebp-4 0xbff2d5f4: 0x41414141 (gdb) x/x $ebp-8 0xbff2d5f0: 0x00000000 (gdb) x/s 0xbff2d5f8 0xbff2d5f8: "A" (gdb) x/s 0xbff2d5f4 0xbff2d5f4: "AAAAA" (gdb)
我们输入更多数据,8个字符:AAAAAAAAA
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 (gdb) r The program being debugged has been started already. Start it from the beginning? (y or n) y Starting program: /home/bodo/testbed5/testbuff Breakpoint 1, main (argc=1, argv=0xbfed9484) at testbuff.c:14 14 Test(); (gdb) s Test () at testbuff.c:7 7 printf("Some input: "); (gdb) 8 gets(buff); (gdb) Some input: AAAAAAAA 9 puts(buff); (gdb) x/x $ebp 0xbfed93d8: 0x41414141 (gdb) x/x $ebp-4 0xbfed93d4: 0x41414141 (gdb) x/x $ebp-8 0xbfed93d0: 0x00000000 (gdb) x/x $ebp+4 0xbfed93dc: 0x08048400 (gdb) x/s 0xbfed93d8 0xbfed93d8: "AAAA" (gdb) x/s 0xbfed93d4 0xbfed93d4: "AAAAAAAA" (gdb) x/x $esp 0xbfed93d0: 0x00000000 (gdb) x/x $esp+4 0xbfed93d4: 0x41414141 (gdb) x/x $esp+8 0xbfed93d8: 0x41414141 (gdb) x/x $esp+12 0xbfed93dc: 0x08048400 (gdb)
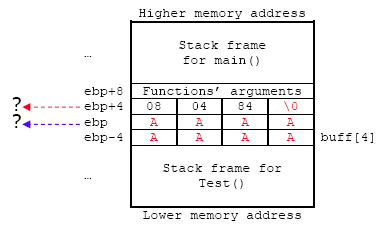
输入 8 个字符后,我们用 0x41414141 和部分返回地址完全覆盖了 ebp(保存的帧指针)。 从gdb:
原来保存的 %ebp =0xbfea2fd8
被覆盖的 %ebp =0x41414141
原始返回地址 = 0x08048427
被覆盖的返回地址 = 0x08048400
接下来,输入更多数据,12 个字符:AAAAAAAAAAAA。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 (gdb) r The program being debugged has been started already. Start it from the beginning? (y or n) y Starting program: /home/bodo/testbed5/testbuff Breakpoint 1, main (argc=1, argv=0xbff43764) at testbuff.c:14 14 Test(); (gdb) s Test () at testbuff.c:7 7 printf("Some input: "); (gdb) 8 gets(buff); (gdb) Some input: AAAAAAAAAAAA 9 puts(buff); (gdb) x/x $ebp 0xbff436b8: 0x41414141 (gdb) x/x $ebp-4 0xbff436b4: 0x41414141 (gdb) x/x $ebp-8 0xbff436b0: 0x00000000 (gdb) x/x $ebp+4 0xbff436bc: 0x41414141 (gdb) x/x $ebp+8 0xbff436c0: 0x00000000 (gdb) x/x 0xbff436b8 0xbff436b8: 0x41414141 (gdb) x/s 0xbff436b8 0xbff436b8: "AAAAAAAA" (gdb) x/s 0xbff436b4 0xbff436b4: 'A' <repeats 12 times> (gdb) x/s 0xbff436bc 0xbff436bc: "AAAA" (gdb)
好吧,当我们输入更多数据时,在这里输了“AAAAAAAAAAAA”,12 个“A”字符(12 个字节); 函数的返回地址也会被覆盖! 当此返回地址恢复(从堆栈中弹出并加载到 %eip 中)时,执行流程将在无效地址 0x41414141 处继续,从而产生分段错误。 保存的 %ebp 和函数的返回地址已损坏。 在真正的漏洞利用中,返回地址将被攻击者想要的有意义的地址覆盖,例如指向已经存储有恶意代码的堆栈区域或系统库或系统中可用的其他易受攻击的应用程序/程序。
在这个例子中,我们测试了我们的程序,只使用了一个包含四个元素的数组,这些元素刚刚填充了堆栈帧的局部变量区域,然后我们成功地覆盖了函数的返回地址。 那么,我们要在哪里存储我们的漏洞利用代码? 具体到这个例子,当使用5或6个元素的数组进行测试时,通过反汇编程序,生成分段错误所需的输入是24个字符(23 + NULL)。 在这种情况下,函数堆栈帧中的缓冲区与局部变量区一起用于临时存储的 get() 和 puts() 操作。 这为我们提供了一个注入漏洞利用代码的区域。 堆栈帧的布局假设如下所示:
这里的思路是,如果我们想做简单的exploit,可以从Buffer区开始填到Local变量,保存的%ebp和函数返回地址。
典型的基本缓冲区溢出漏洞利用将尝试用指向恶意代码已注入缓冲区的地址覆盖返回地址,如下所示。
代码注入之前:
注入之后:
典型的利用漏洞利用方法将恶意代码注入堆栈的同一程序缓冲区,从而溢出堆栈缓冲区的典型布局如下所示。
作为结论,缓冲区溢出攻击的一般形式实际上试图实现以下两个目标:
1.注入攻击代码(在程序中对输入进行硬编码,来自命令行或网络字符串的用户输入/通过套接字的输入重定向——远程攻击或其他高级方法)。
2.改变运行进程的执行路径来执行攻击代码(通过覆盖返回地址)。
需要注意的是,这两个目标是相互依赖的。 通过注入没有执行能力的攻击代码不一定是漏洞。
THE STACK BASED BUFFER OVERFLOW EXPLOIT VARIANT 在了解基于堆栈的缓冲区溢出操作的基本原理后,让我们研究用于漏洞利用的变体。
第一种情况如前面的示例中所述。 此漏洞利用通常使用具有缓冲区溢出漏洞的应用程序/程序。 漏洞利用可以欺骗函数或子例程将比可用空间更多的数据放入其缓冲区。 多余的数据将存储在固定大小的缓冲区(已通过数组等在程序中声明)之外,包括存储返回地址的内存位置。 通过覆盖返回地址,该地址保存了函数任务完成时要执行的代码的内存位置的地址,漏洞利用程序可以控制子程序完成时要执行的代码。 这种类型的缓冲区溢出漏洞已通过多种方式受到保护。
利用缓冲区溢出的第二种情况只是覆盖函数的返回地址。 然而,它不是用缓冲区中的代码地址覆盖它,而是用一个函数或其他对象的地址覆盖它,这些对象已经存在于正在运行的应用程序中,例如具有缓冲区溢出漏洞的共享 glibc 库。 以前,在实施任何缓冲区溢出保护之前,这些函数已经加载到系统固定地址的内存中。 这种类型的攻击不依赖于在堆栈区域上执行代码,而是依赖于执行现有的合法代码。 此漏洞通常与其他类型的漏洞结合使用,例如作为恶意输入的格式字符串和 Unicode
与基本堆栈溢出一样,攻击者必须知道堆栈上缓冲区的大致地址,实际上很容易获得。 例如,每个运行完全相似版本的 Linux OS 的系统基本上都有相似的应用程序、二进制文件和库。 由于这些相似性,许多操作系统的抢手地址非常相似或相同。 编写漏洞利用程序的人只需检查自己的系统,以确定与所有其他此类系统相似的地址。 例如,这对于 Red Hat Linux 来说并不是唯一的。 这种类型的漏洞利用也受到多种方式的保护。
Windows 操作系统也有同样的问题,但每个版本的 Windows 操作系统(如 Windows 2000 Server 和 Windows Xp Pro 版本)对应用程序中存在的功能都有不同的地址。 这些函数通常是 Win32 函数。 请记住,相同版本的 Windows 操作系统但具有不同的 Service Pack (SP) 或补丁程序,这些函数和库的位置也可能不同。 虽然每个版本的 Windows 操作系统都有不同的 Win32 函数地址,但幸运的是,这些地址可以在标准的 Windows 操作系统文档中找到,也可以通过使用第三方程序如 PE 浏览器(http://www.smidgeonsoft.prohosting.com/ ) 实用程序,适用于相应的 Windows 操作系统版本。
此漏洞利用的一个示例是 return-to-libc。 它是一种计算机安全攻击,通常以缓冲区溢出开始,其中堆栈上的返回地址被程序中共享库的另一个函数(例如 printf() 家族(使用格式字符串漏洞)的地址)替换。 这允许攻击者在不向程序中注入恶意代码的情况下调用现有的易受攻击的函数,并且仍然可能成为受non-executable stack 等概念保护的环境中的安全漏洞。
对于高级和更新的漏洞利用,他们曾经覆盖其他地址,例如:
函数指针。
程序 ELF 的 GOT 指针 (.got)。
程序 ELF 的 DTORS 部分 (.dtors)。
不幸的是,对于黑客来说,这种类型的缓冲区溢出漏洞也得到了许多保护。 例如在 Red Hat Enterprise Linux v.3, update 3 中,一个补丁程序,
(警告:链接是一个 pdf 文档)随机分配程序的以下组件的地址:
Locations of shared libraries.
The stack itself.
The start of the programs heap.
因此无法再猜测地址,因此几乎不可能找到这些漏洞利用所需的确切地址; 现在每台机器的地址都不同,并且每次程序启动时都不同。